Welcome to Ryan Liao’s Portfolio
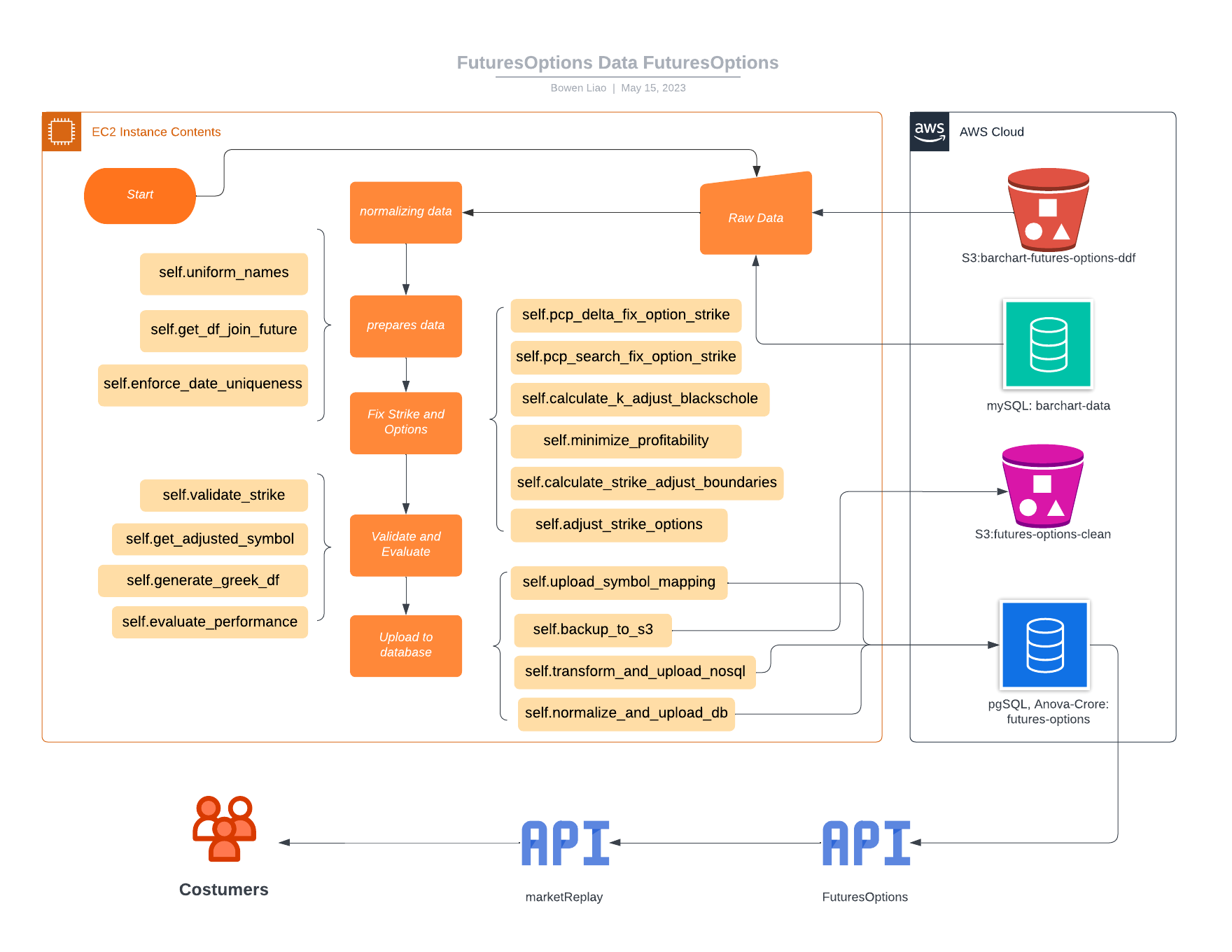
Futures Options Data Product
Chicago, IL Oct 2022 –> Jun 2023
- Spearheaded a significant data transformation project, converting historical futures options data into a high-revenue data product (approx. $200K p.a.), solidifying Barchart’s position in the financial data market
- Devised an original mathematical theorem to capture asset price relationships through rigorous data analysis, establishing the fundamental algorithm for advanced data cleaning and quality enhancement
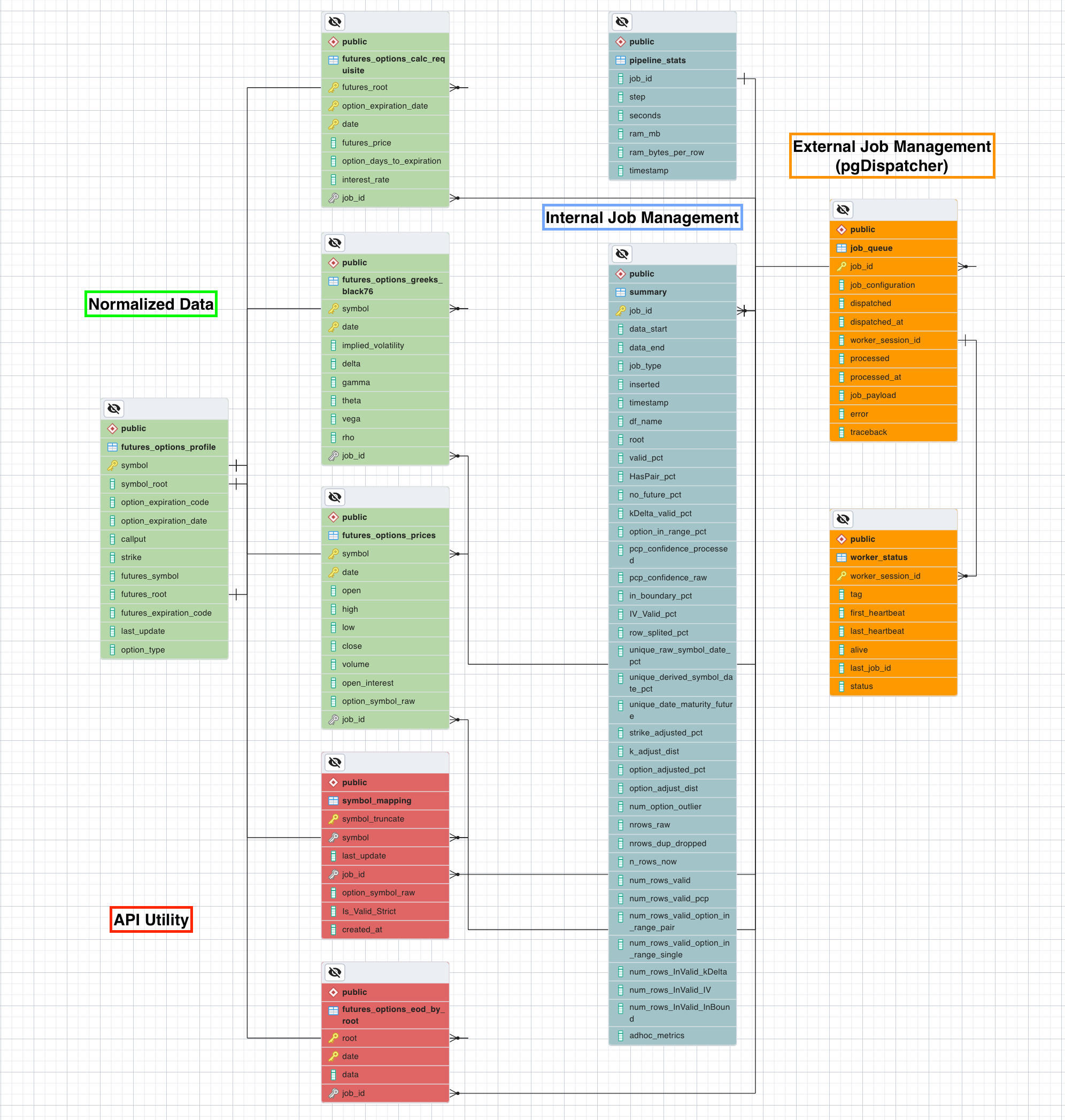
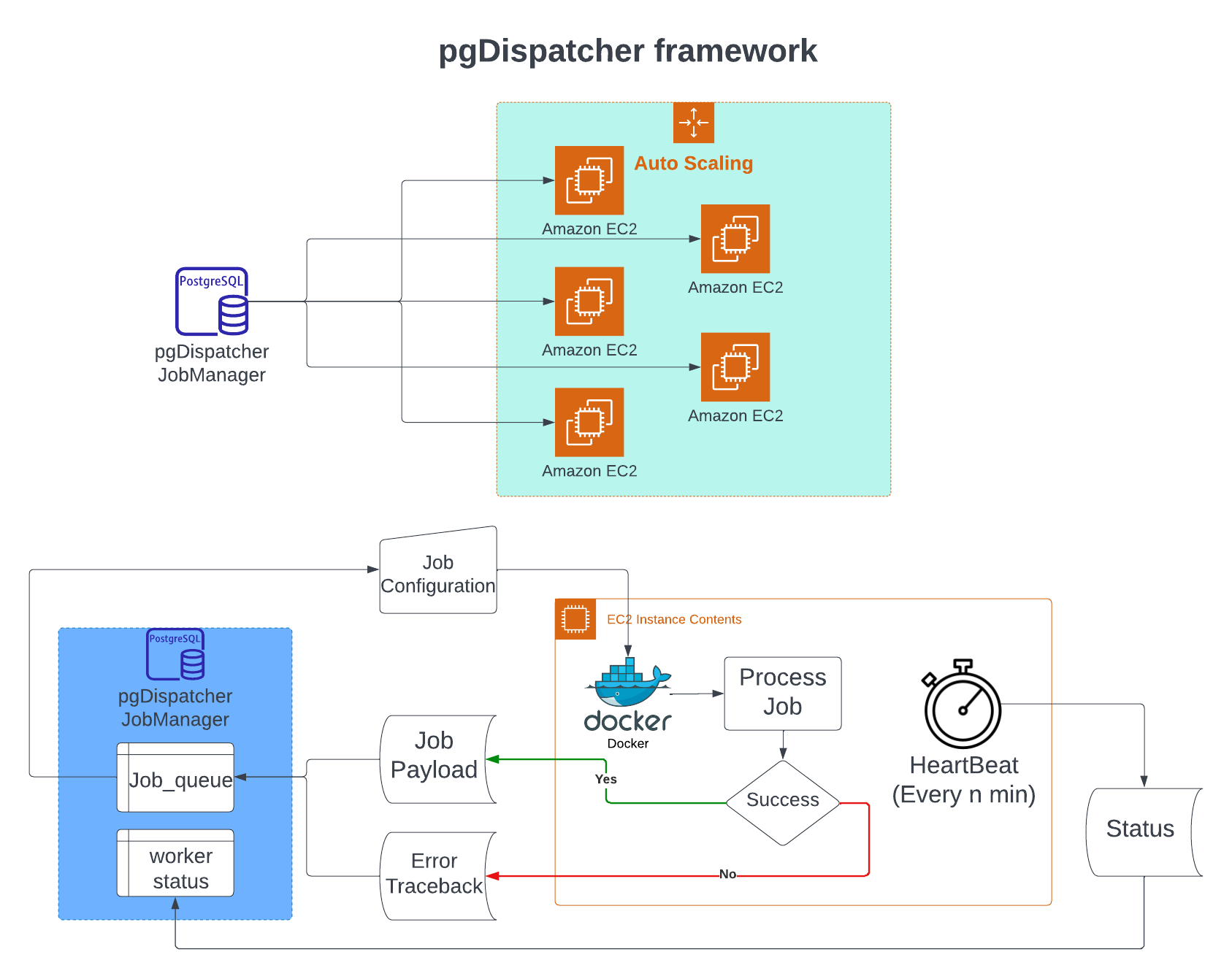
pgDispatcher Parallel Computing Framework
Chicago, IL Feb 2023 –> May 2023
- Developed and packaged ‘pgDispatcher’, a serverless framework using PostgreSQL Database and AWS autoscaling EC2 instances, into a Python library for efficient multiprocessing management
- Accelerated data cleaning jobs from a 2-year timeline to 2 days using docker on an auto-scaling cluster with 200 instances and ensured knowledge transfer through comprehensive documentation and workshops
Basis Forecasting Machine Learning Operation
Chicago, IL July 2022 –> Septembr 2022
- Plan, analysis, design, implement and maintain scalable data ETL pipelines from end-to-end that extract, clean and engineer data to be feed into AWS-SageMaker
- Automate training, deploying and evaluating metrics agaisnt industry standards with latest data using Crontab on AWS-EC2
- Tuning State of the art DeepAR models to achieve a model which has error 40% fewer than the industry standards
.png)
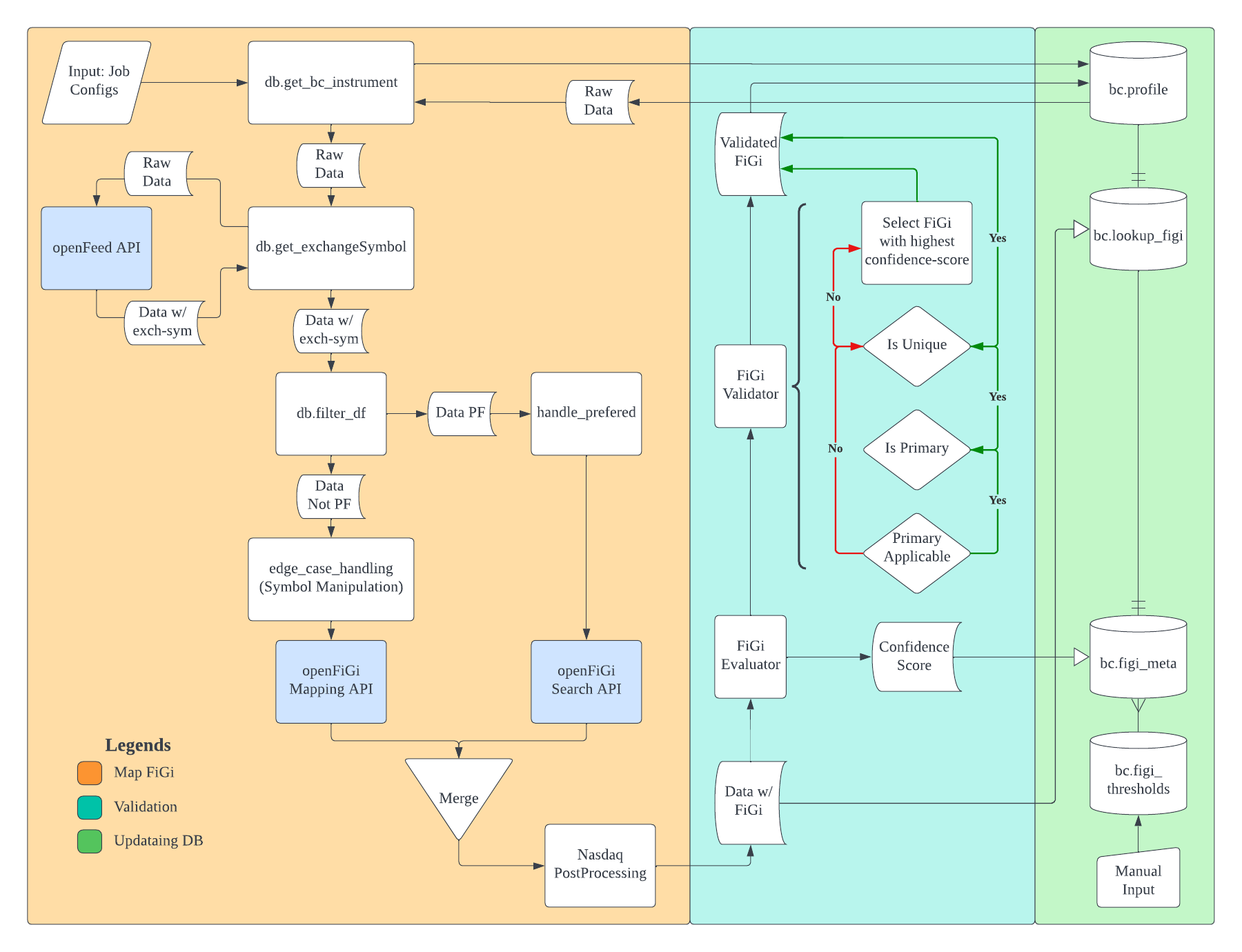
OpenFiGi ETL Pipeline
Chicago, IL June 2022 –> August 2022
- Engineering ETL pipelines that orchestrate database insertion, update, and recall on daily basis automated through AWS, ensuring data integrity by overcoming API design flaws at minimum costs
- Maps vendor-symbol to Bloomberg’s global FiGi, supported over 80000 new instruments across Equity, ETF, UIT, Mutual Funds, and Index
- Design and implement validation pipelines that quantify mapping reliability, then conducted Anomaly Detection using Clustering Analysis for mapping Failure Prediction, identified over 70% of the mapping errors
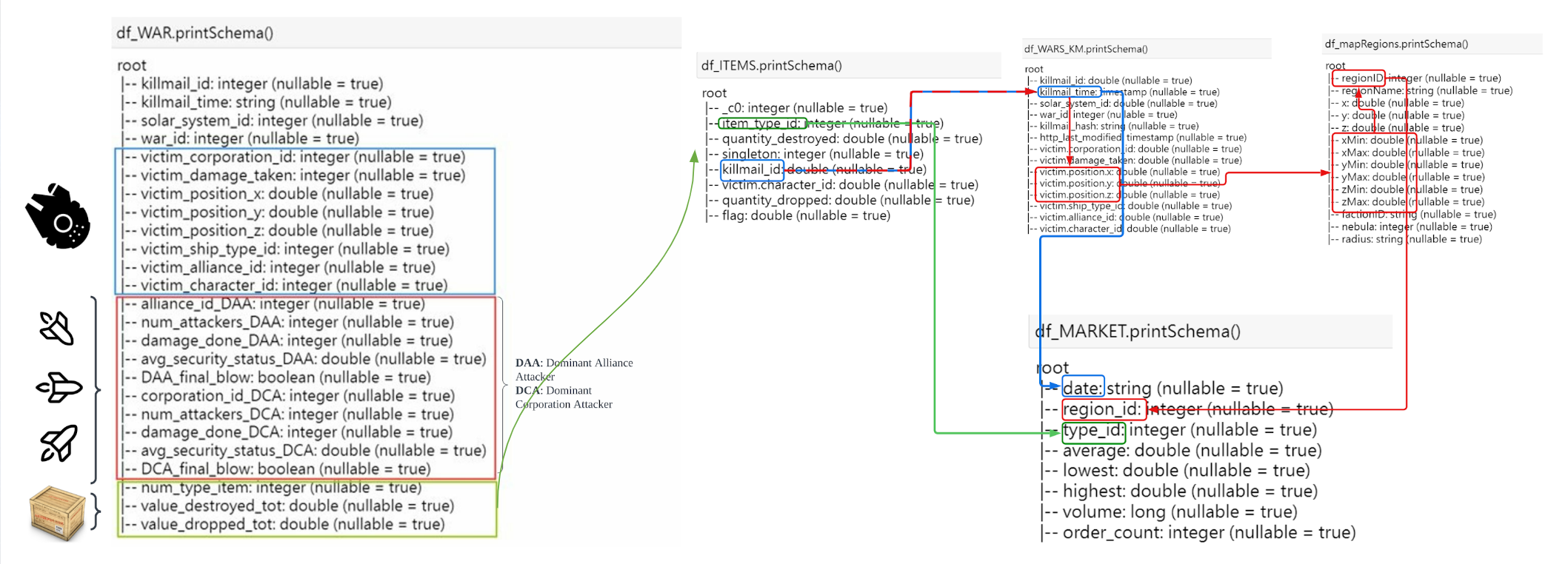
EVE-Online BigData Project
Chicago, IL Apr 2022 –> June 2022
Get this Data on Kaggle
- Create databases on Hadoop, and Google Storage that contains over 200Gs of data to be analyzed on PySpark through virtual machine clusters on Google Dataproc
- Optimize ETL data pipelines through multiprocessing to speed the entire preprocessing process by over 99%
- Leverage both Big Query and PySpark to flatten NoSQL data into structured ones and engineer new features by joining multiple tables
- Built model pipelines that clean, cross-validate, and tune hyperparameters to predict warfare outcomes using PySpark MLlib

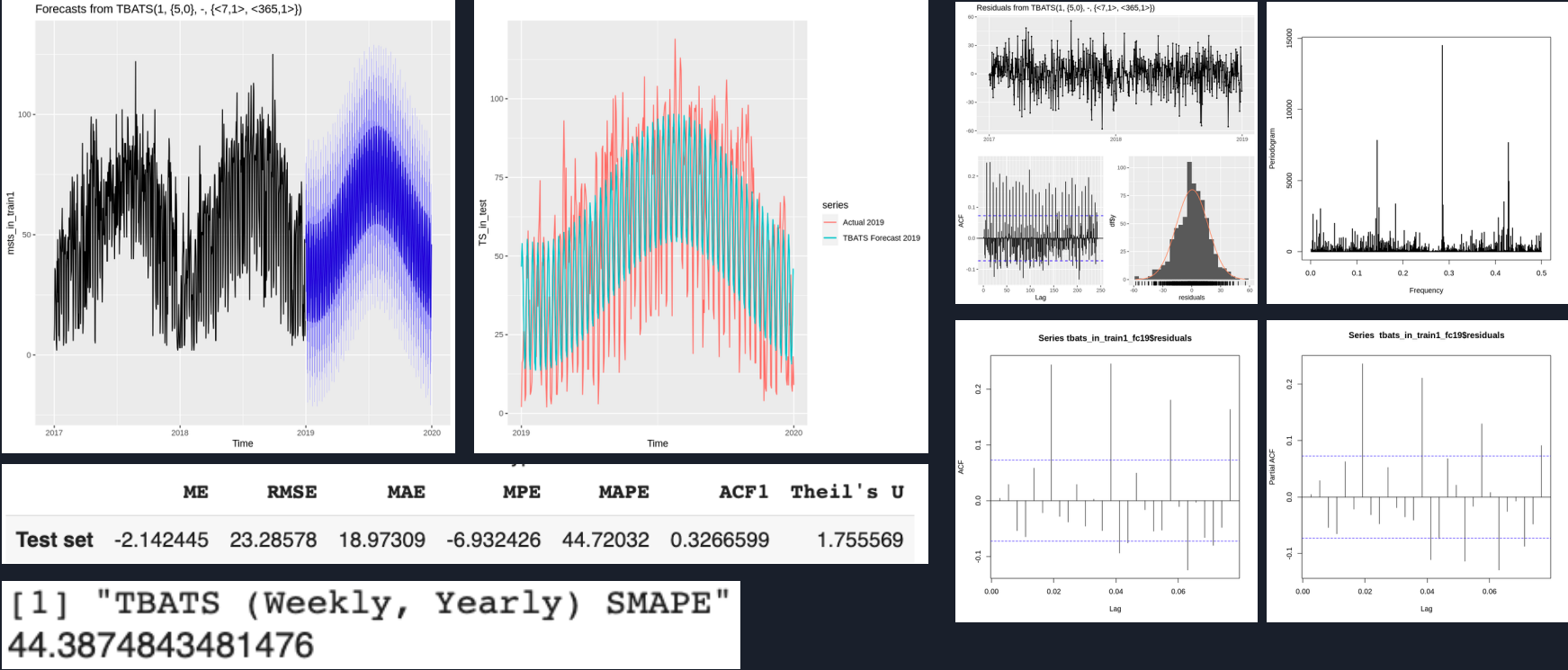
Divvy bike #2: Time Series Forecasting
Chicago, IL Apr 2022 –> June 2022
Get this Data on Kaggle
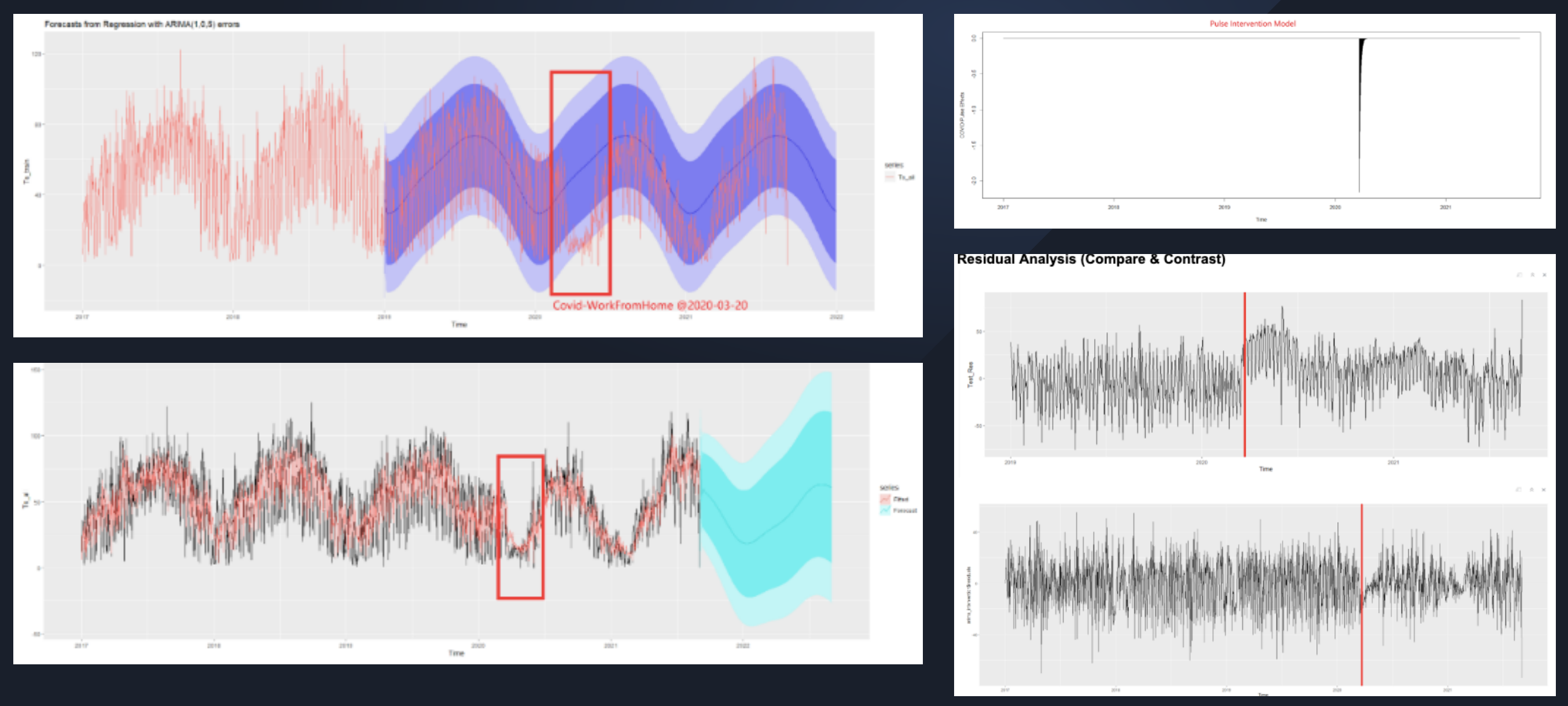
- Conduct thorough time series EDA on its trend, intervention, outliers, stationarity, seasonality, and forecastability to guide and engineer data for better model performance
- Cluster panel data across over 1000 stations and 5 years into 2 clusters using K-means to distinguish stations that were impacted by Covid to be modeled separately.
- Map station-ID to Neighborhood-ID based on coordinates collected from Google geo-encoding API, thus connecting with originally disconnected tables and aggregating horizontally to increase data forecastability
- Forecast station traffic and dock availability using an ensembled model of VARMA and frequency-based multi-seasonal SARIMA in real-time to guide the maintenance intervention ahead of time to prevent station overload
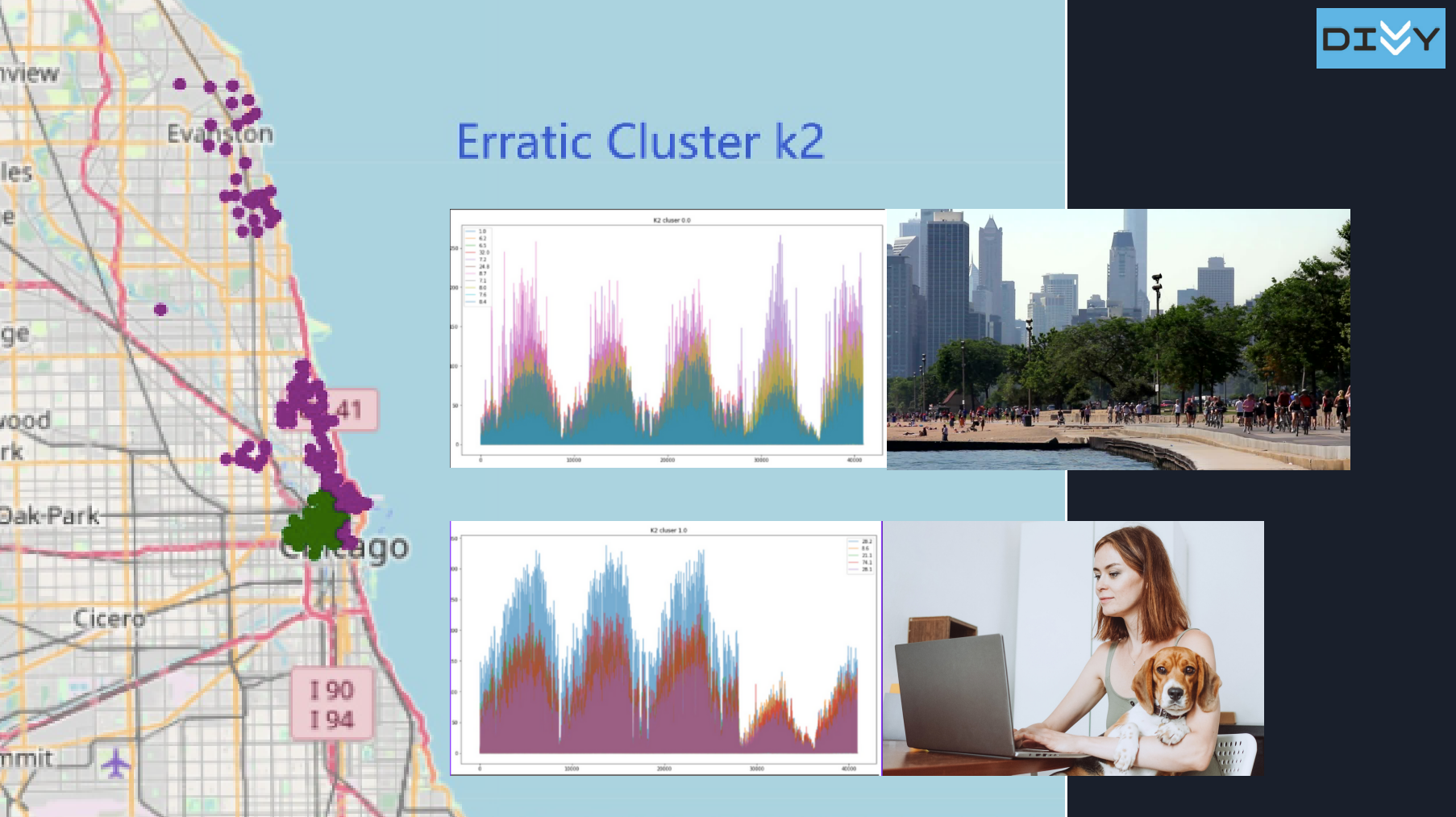
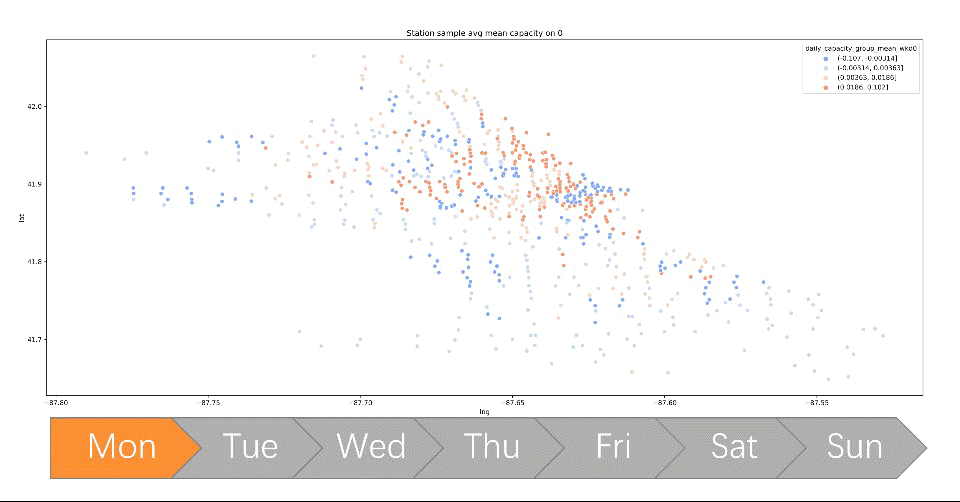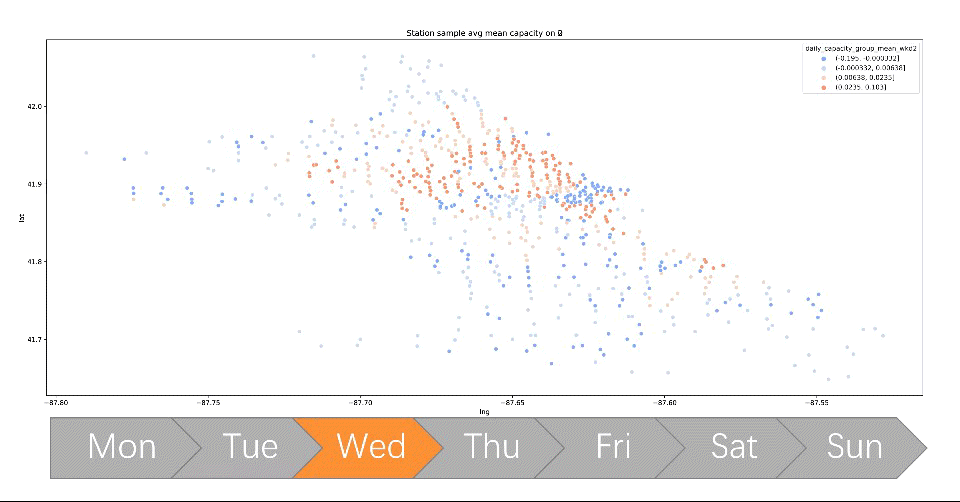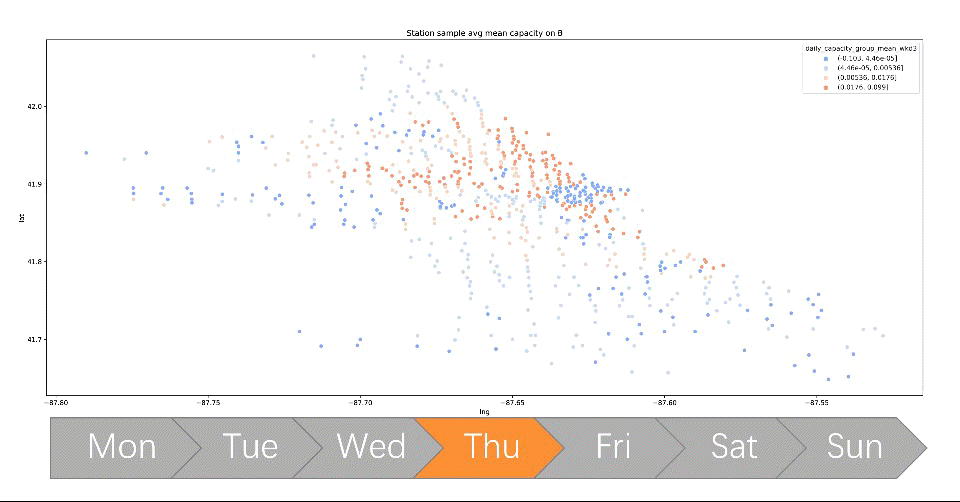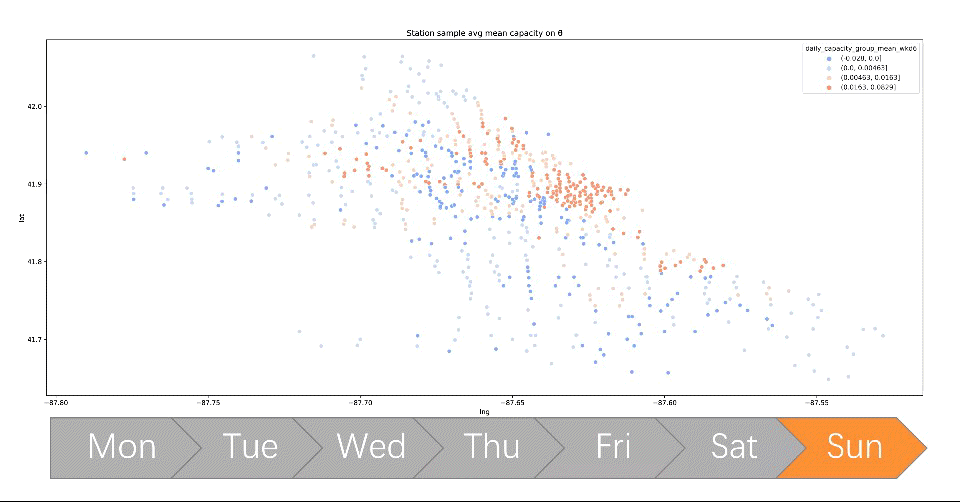
Divvy bike #1: Dock Balancing Analysis
Chicago, IL Jan 2022 –> Apr 2022
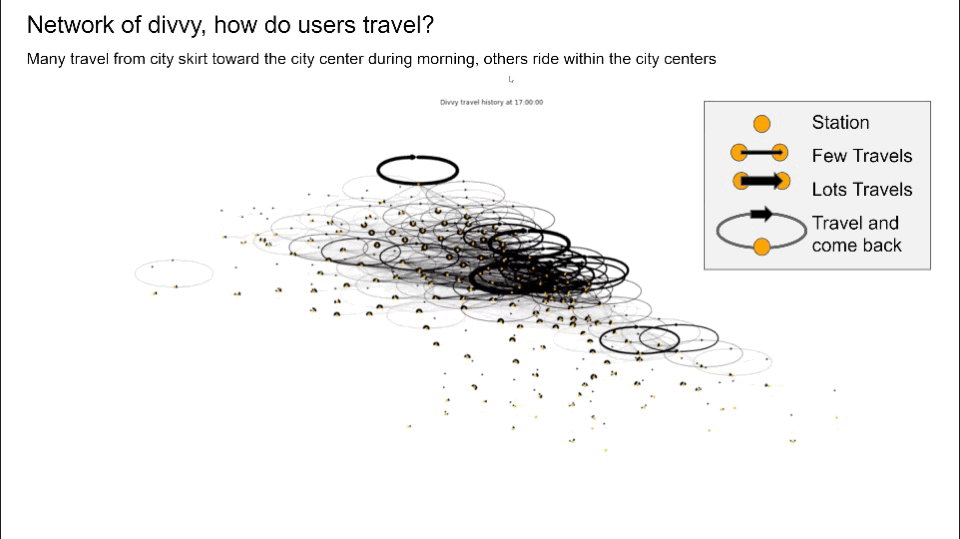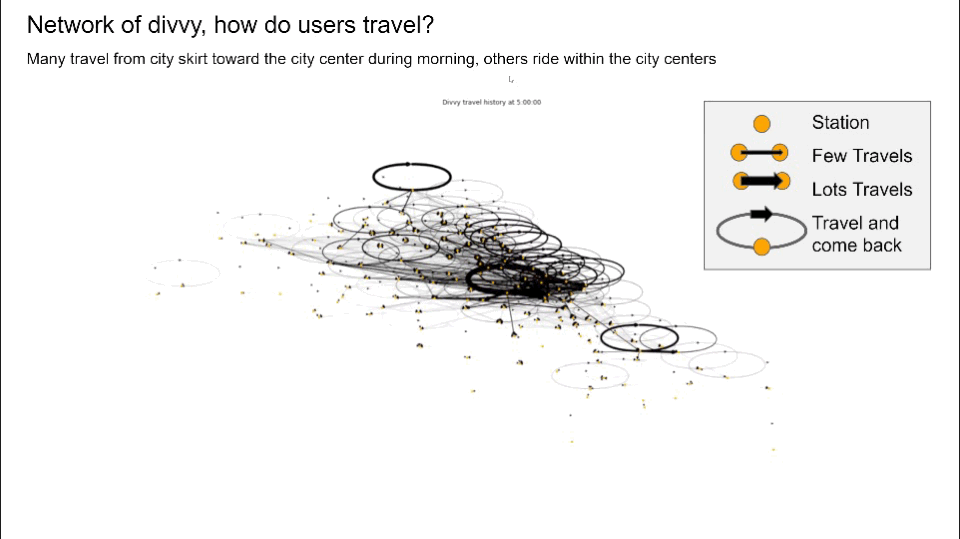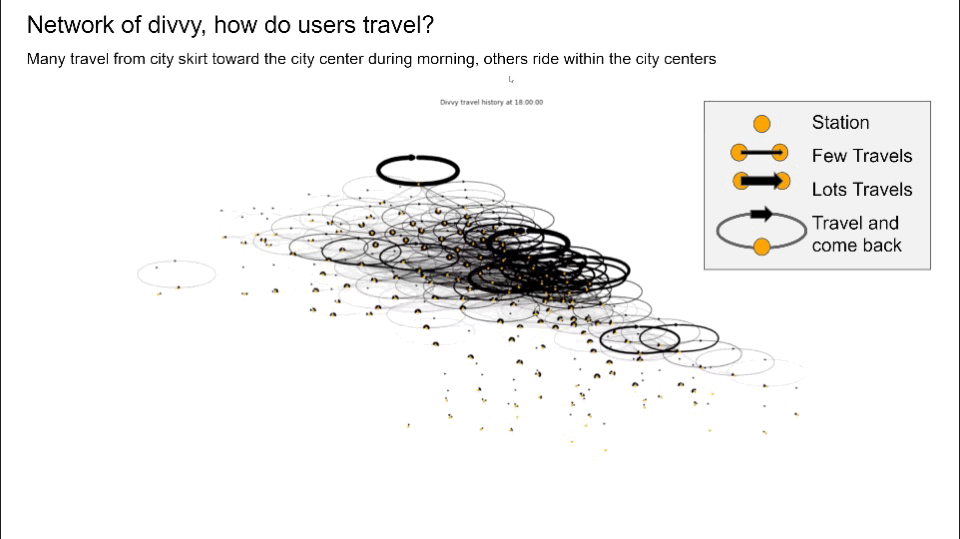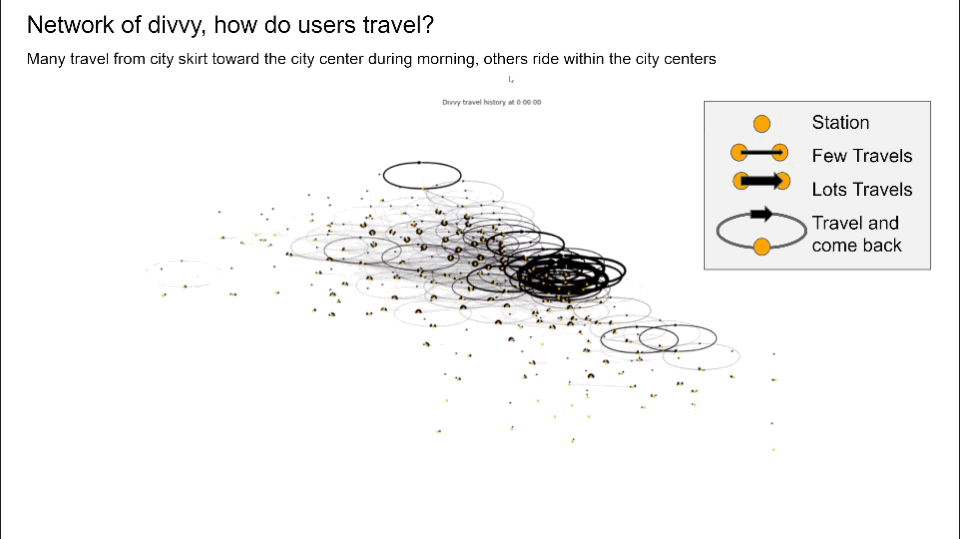
- Converted structured travel history into graphs and generated network graphs using Networkx, visualized user travel patterns to identify potential communities suffering from bike balancing problems, and pinpoint top stations by calculating node centrality
- Mapped station-ID to Neighborhood-ID based on coordinates collected from Google geo-encoding API, thus connecting with originally disconnected relational databases and reducing dimension by over 80%
- Created new features that keep track of all dock’s capacity by simulating over travel history data, visualizing each station’s dock availability which directly addresses the capacity imbalance problem
- Performed clustering on each station’s dock capacity trend using k-means, leading to insights that generated client-ready visualization and solution that has an NPV equivalent to 36% annual revenue in the estimate
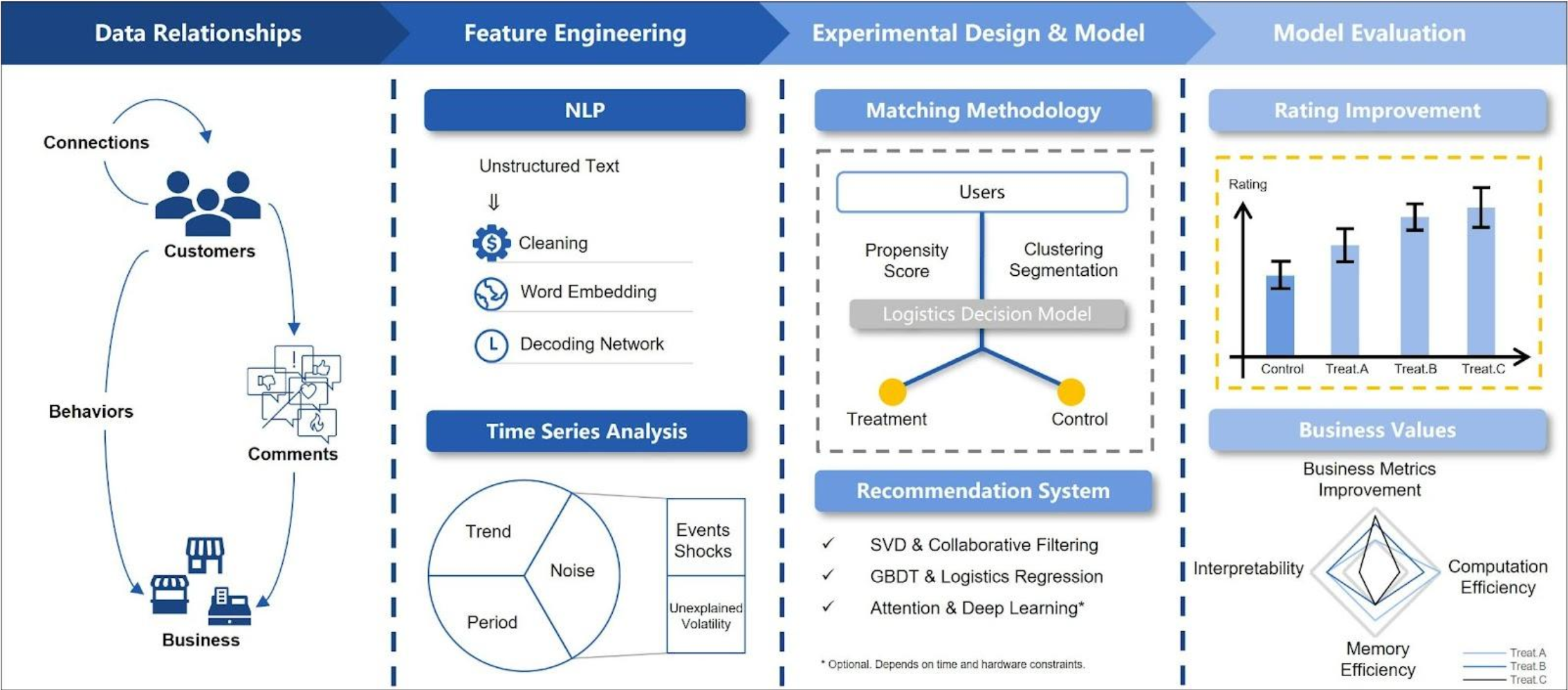
Yelp’s recommendation system
Chicago, IL Jan 2022 –> Apr 2022
- Built databases and environments on remote servers using Hadoop through Ubuntu to facilitate teamwork
- Reprogrammed feature engineering pipeline through NumPy vectorization and programming techniques to not only boost total running time by 5 times but also solved memory overflow issues due to huge dataset
- Conducted time series analysis using Facebook Prophet, broke down review trend by its seasonality, and guided the generation of time-related features
- Implemented a content-based collaborative filtering recommendation engine that has an NDCG of 0.92
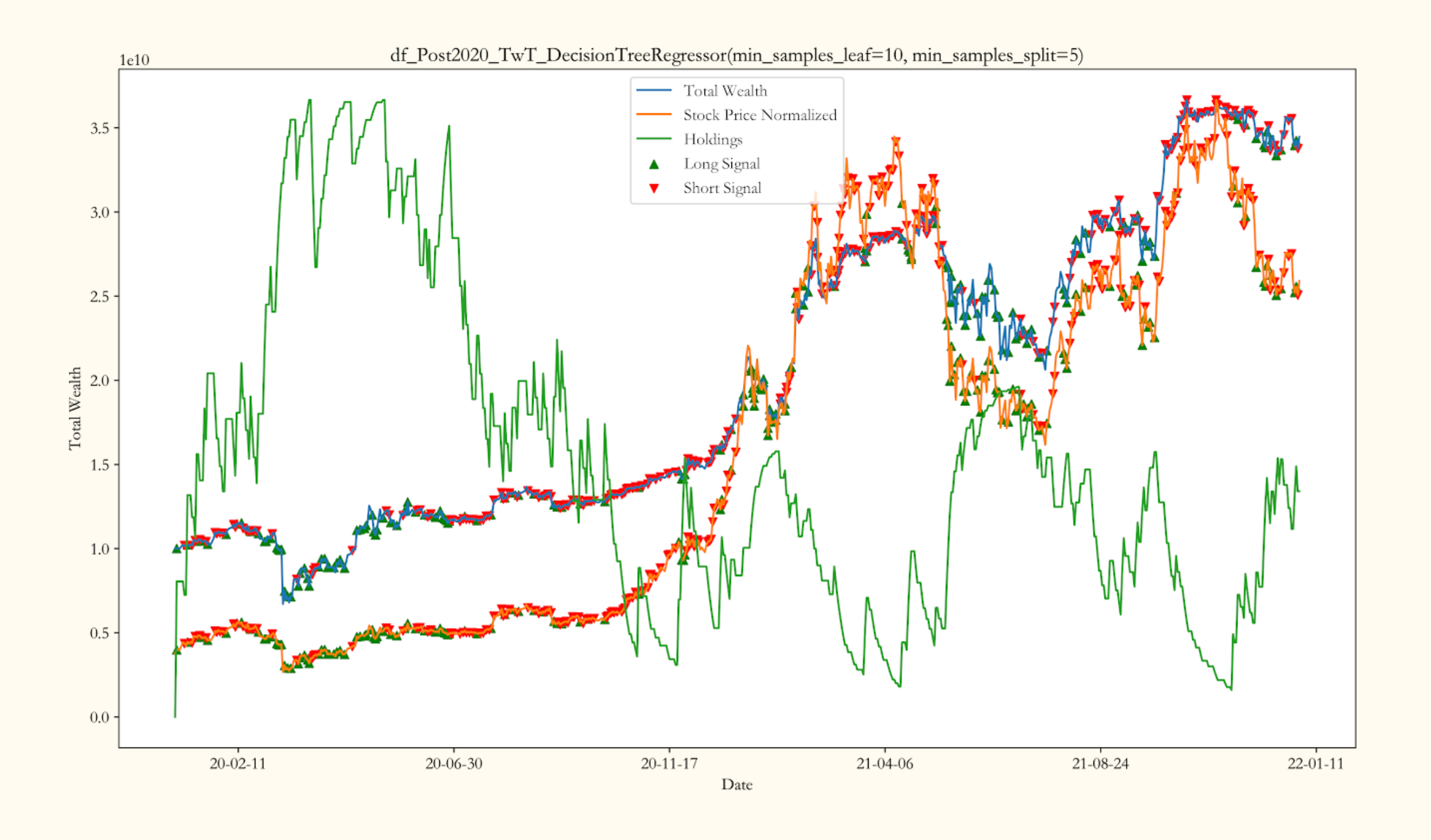
Realtime Intelligent Crypto Trading System
Chicago, IL Jan 2022 –> Apr 2022
- Collected streaming data from social media using python sockets, API requests, selenium, and beautiful soup to build a database to explore correlation with Bitcoin prices
- Cleaned bot-generated data by first manually tagging tweets through shared patterns, then cluster tweets using k-means to bulk identify, eventually increasing tweet subjectivity by over 40%
- Performed sentimental analysis on social media activities along with the tweet volume, transaction volume, and google search trends to build models which predict Bitcoin price fluctuations with an R-square of 0.93
- Constructed server and client that handles streaming data of Bitcoin prices and tweeter, predicts future price
and generates trading signals in real-time that out-performs baseline algorithm in backtesting by over 2000%